[译] Java Volatile 关键字详解
文章目录
本文翻译自 Java Volatile Keyword
Java关键字volatile用于将一个Java变量标记为 在主内中存储 ,更准确的解释为:每次读取一个 volatile 变量时将从电脑的主内存中读取而不是从CPU缓存中读取,每次对一个 volatile 变量进行写操作时,将会写入到主内存中而不是写入到CPU缓存中。
事实上,从Java5之后,volatile 关键字不仅仅可以用来确保 volatile 变量是写入到主内存和从主内存读取数据,我会在下面的章节进行详细的介绍:
Volatile变量可见性保证
Java volatile 关键字确保了 volatile 变量的修改在多线程中是可见的。这听起来有些抽象,接下来我将详细说明。
在一个对非 volatile 变量进行操作的多线程应用,由于性能的关系,当对这些变量进行读写时,每个线程都可能从主线程中拷贝变量到CPU缓存中。如果你的电脑不止一个CPU,每个线程可能会在不同的CPU上运行。这意味着,每个线程都可能将变量拷贝到不同的CPU的CPU缓存中,如下图所示:
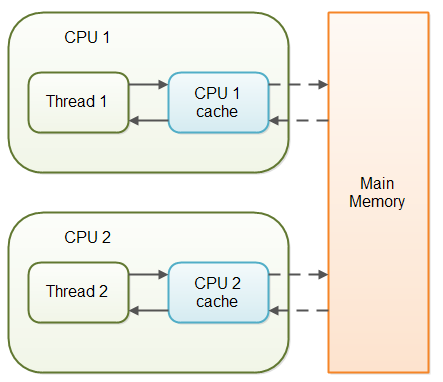
对于非 volatile 变量而言,Java虚拟机(JVM)不能确保什么时候将数据从主内存读取到CPU缓存以及什么时候将CPU缓存的数据写入到主内存中。而这可能会引起一些问题,我将稍后解释。
假设两个或更多的线程对下面这个包含一个计数器的共享变量拥有访问权限:
|
|
再次假设,只有Thread1会增加 counter 变量的值,但是Thread1和Thread2都能在任意时刻读取 counter 变量的值。
如果 couner 变量没有声明为 volatile 将无法保证在何时把CPU缓存中的值写入主内存中。这意味着 counter 变量在CPU缓存中的值可能会与主内存中的值不一样,如下所示:
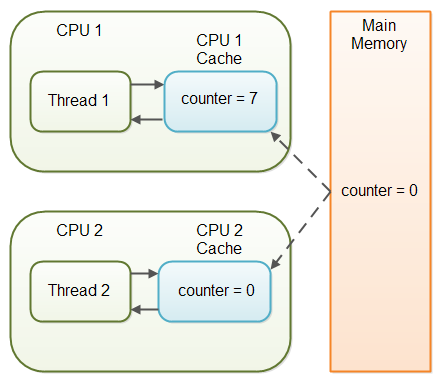
造成线程不能获取变量最新值得原因为变量值没有被其它线程及时写回主内存中,这就是所谓的可见性问题。某个线程的更新对其它线程不可见。
将 counter 变量声明为 volatile 之后,所有对 counter 变量的写操作会立即写入主内存中,同样,所有对 counter 变量的读操作都会从主内存中读取数据。下面的代码块展示了如何将 counter 变量声明为 volatile :
|
|
因此定义一个 volatile 变量可以保证写变量的操作对于其它线程可见。
Volatile先行发生原则
从Java5之后 volatile 关键字不仅能用于确保变量从主内存中读取和写入,事实上,volatile 关键字还有如下作用:
- 如果线程A写入了一个 volatile 变量然后线程B读取了这个相同的 volatile 变量,那么所有在线程A写之前对其可见的变量,在线程B读取这个 volatile 之后也会对其可见。
- volatile 变量的读写指令不能被JVM重排序(出于性能的考虑,JVM可能会对指令重排序如果JVM检测到指令排序不会对程序运行产生变化)。
前后的指令可以重排序,但是 volatile 变量的读和写不能与这些重排序指令混在一起。任何跟随在 volatile 变量读写之后的指令都会确保只有在变量的读写操作之后才能执行。
上述说明需要更进一步的解释。
当一个线程向一个 volatile 变量写操作,此时不仅这个 volatile 变量自身会写入主内存,所有这个 volatile 变量写入之前受影响发生改变的变量也会刷写入主内存。当一个线程向一个 volatile 变量读操作时它同样也会从主内存中读取所有和这个 volatile 变量一起刷写入主内存的变量。
看看下面这个示例:
|
|
由于线程A在写操作 volatile 变量 sharedObject.counter 之前写操作非 volatile 变量 sharedObject.nonVolatile ,因而当线程A写操作变量 sharedObject.counter 后,变量 sharedObject.nonVolatile 和 sharedObject.counter 都被写入主内存。
由于线程B以读取 volatile 变量 sharedObject.counter 开始,因而变量 sharedObject.counter 和变量sharedObject.nonVolatile 都会被写入线程B所使用的CPU缓存中。当线程B读取 sharedObject.nonVolatile 变量时,它将能看见被线程A写入的变量。
开发人员可以利用这个扩展的可见性来优化线程之间变量的可见性。不同于把每个变量都设置为 volatile ,此时只有少部分变量需要声明为 volatile 。下面是一个利用此规则编写的简单示例程序 Exchanger :
|
|
线程A随时可能会通过调用 put() 方法增加对象,线程B随时可能会通过调用 take() 方法获取对象。只要线程A只调用 put() ,线程B只调用 take() ,这个 Exchanger 就可以通过一个 volatile 变量正常工作(排除 synchronized 代码块的使用)。
然而,JVM可能会重排序Java指令来优化性能,如果JVM可以通过不改变这些重排序指令的语义来实现此功能。如果JVM调换了 put() 和 take() 中的读和写的指令,会发生什么呢?如果 put() 真的像下面这样执行会出现什么情况呢?
|
|
请注意此时对于 volatile 变量 hasNewObject 的写操作会在新变量的实际设置前先执行,而这在JVM看来可能会完全合法。两个写操作指令的值不再依赖于对方。
但是,对于执行指令重排序可能会损害 object 变量的可见性。首先,线程B可能会在线程A对 object 真实的写入一个值到object之前读取到 hasNewObject 的值为true。其次,现在甚至不能保证什么时候写入 object 的新值会刷写入主内存(好吧,下次线程A在其它地方写入 volatile 变量。。。)
为了阻止上面所述的这种情况发生, volatile 关键字提供了一个 先行发生原则。先行发生保证确保对于 volatile 变量的读写指令不会被重排序。程序运行中前后的指令可能会被重排序,但是 volatile 读写指令不能和它前后的任何指令重新排序。
看看下面这个例子:
|
|
JVM可能会重新排序前3条指令,只要它们都先发生于 volatile 写指令(它们都必须在 volatile 写指令之前执行)。
同样的,JVM可能会重新排序最后3条指令,只要 volatile 写指令先行发生于它们,这3条指令都不能被重新排序到 volatile 指令的前面。
这就是 volatile 先行发生原则的基本含义。
Volatile并不是万能的
尽管 volatile 关键字确保了所有对于 volatile 变量的读操作都是直接从主内存中读取的,所有对于 volatile 变量的写操作都是直接写入主内存的,但仍有一些情况只定义一个 volatile 变量是不够的。
在前面的场景中,线程1对共享变量 counter 写入操作,声明 counter 变量为 volatile 之后就能够确保线程2总是可以看见最新的写入值。
事实上,如果写入该变量的值不依赖于它前面的值,多个线程甚至可以在写入一个共享的 volatile 变量时仍然能够持有在主内存中存储的正确值。换句话解释为,如果一个线程在写入volatile共享变量时,不需要先读取该变量的值以计算下一个值。
一旦一个线程需要首先读取一个 volatile 变量的值,然后基于该值产生 volatile 共享变量的下一个值,那么该 volatile 变量将不再能够完全确保正确的可见性。在读取 volatile 变量和写入它的新值这个很短的时间间隔内,产生了一个 竞争条件 :多个线程可能会读取 volatile 变量的相同值,然后产生新值并写入主内存,这样将会覆盖互相的值。
这种多个线程同时增加相同计数器的场景正是 volatile 变量不适用的地方,接下来的部分进行了更详细的解释。
假设线程1读取一个值为0的共享变量 counter 到它的CPU缓存中,将它加1但是并没有将增加后的值写入主内存中。线程2可能会从主内存中读取同一个 counter 变量,其值仍然为0,同样不将其写入主内存中,就如下面的图片所展示的那样:
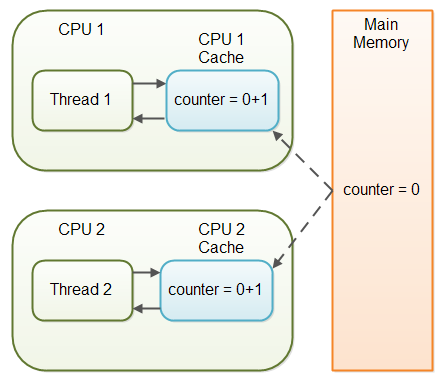
线程1和线程2现在都没有同步,共享变量 counter 的真实值应该是2,但是在每个线程的CPU缓存中,其值都为1,并且主内存中的值仍然是0。它成了一个烂摊子,即使这些线程终于它们对共享变量 counter 的计算值写入到主内存中,counter 的值仍然是错的。
Volatile的适用场景
就如在前面提到的那样,如果两个线程同时对一个共享变量进行读和写,那么仅用 volatile 变量是不够的。在这种情况下,你需要使用 synchronized 来确保关于该变量的读和写都是原子操作。读或写一个 volatile 变量时并不会阻塞其它线程对该变量的读和写。在这种情况下必须用 synchronzied 关键字来修饰你的关键代码。
除了使用 synchronzied 之外,你也可以使用 java.util.concurrent 包中的一些原子数据类型,如 AtomicLong , AtomicReference 等。
当只有一个线程对一个 volatile 变量进行读写而其它线程只读取该变量时, volatile 可以确保这些读线程读取到的是该变量的最新写入值。如果不声明该变量为 volatile ,则不能这些读线程保证读取的是最新写入值。
volatile 关键字适用于32位变量和64位变量。
Volatile性能思考
由于 volatile 变量的读和写都是直接从主内存中进行的,相对于CPU缓存,直接对主内存进行读写代价更高, 访问一个 volatile 变量也会阻止指令重新排序,而指令排序也是一个常用的性能增强技术。因此,你应该在只有当你确实需要确保变量可见性的时候才使用 volatile 变量。
<–终于翻译完了!–>
文章作者 飞狐
上次更新 2016-03-07